
Recommender Systems are a Joke - Unsupervised Learning with Stand-Up Comedy
Disclaimer: This post as well as the code accompanying it contains some direct and indirect references to potentially offensive language. This is an analysis of stand-up comedy, which tends to contain curse words, racial slurs, etc. However, all references are made with objective, academic intent. If you have any concerns with my treatment of certain language, I’d be happy to have a conversation. You can get in touch with me via LinkedIn.
This post documents my first foray into unsupervised learning, natural language processing, and recommender systems. I completed this project over a 2-week span during my time as a student at Metis.
The code for this project can be found here. The Flask app I made for this project can be found here.
Intro
 Comedy! (Image: Scraps from the Loft)
Comedy! (Image: Scraps from the Loft)
A little over halfway through the Metis data science bootcamp, the curriculum shifted from
supervised to
unsupervised learning. At that point, my brain was
firmly in “predict y given X” mode, and it quite honestly took a few days to wrap my head around what it means
to use machine learning on unlabeled data, and why that would even be useful. It clicked when I applied a
rudimentary model of the human brain to both of these approaches: often our brains make inferences based
on our previous experiences and knowledge (supervised learning). However, sometimes we are forced to find previously
unseen patterns in the world around us (unsupervised learning) before we can make decisions.
Concurrently, we were introduced to Natural Language Processing (NLP). In addition to learning a lot specifically about NLP, one big takeaway was a clearer understanding of what is meant by “Artificial Intelligence” in the context of machine learning - any instance of a computer being able to imitate (or even replicate) a human perception or ability. After this realization, I went from being somewhat weary of apply machine learning to text/speech, to extremely motivated to work on an NLP problem.
As you might expect, the main requirements of this project were:
- Use unsupervised learning.
- Use text as the primary data source.
I almost instantly came up with an idea. Stand-up comedy specials are usually in a 1-hour monologue format, and are rich and diverse in topics, opinions, colloquialisms, and regional english dialects. For that reason, and also the fact that I’m a huge fan of the comedy world, I knew that this would be a stimulating project.
Data Wrangling
Luckily, I was able to quickly find a website (Scraps from the Loft) with several hundred comedy transcripts. I used the Python requests) library in a script to acquire all of the raw HTML for each transcript, and Beautiful Soup to parse the main text and various metadata (comedian, title of comedy special, year).
After inserting the data into pandas dataframes (one for the metadata and one for the text corpus), I stored it in a remote Mongo database on an Amazon AWS EC2 instance. Admittedly, this wasn’t really necessary as my corpus was small enough to store locally , but I wanted to get more comfortable with both creating MongoDB collections and querying data for analysis and modeling using pymongo.
Data Cleaning & The NLP Pipeline
As we had been warned, cleaning and preparing the text corpus proved to be the most critical, time consuming part of this project. Topic modeling (and clustering) of text data relies on sufficient elimination of extraneous words, but also careful inclusion of words that might be indicators of a topic.
First, I performed some “macro” cleaning, removing entire documents (individual transcripts) that would throw off the modeling and/or not be relevant in a recommender app. That involved removing:
- Comedy specials in different languages (there were a handful in Italian and Spanish).
- Comedy specials that are not widely available (or available at all) on streaming platforms.
- Short-form comedy such as monologues on Saturday Night Live, or other late night TV shows.
I then created an “NLP pipeline”, that can take any document from the corpus and perform the following transformations:
- Clean the text by removing punctuation, non-essential parts like the person introducing the comedian, removing numbers, removing line breaks, crazy noises and expressions like “aaaaah”, and common English stop words.
- “Lemmatized” words to reduce all forms of words to their base or “lemma”. (For example, “studies” and “studying” become “study”). The purpose of this is to extract the core meaning and topics out of the text rather than pay attention to how words are being used in the context of a sentence. The Python NLTK library was very useful for this step and several of the previous steps.
- “Vectorized” the entire corpus. In general, this means converting the long strings of text to tabular format, where each column is a word, each row represents a document in the corpus (also known as a doc-term matrix), and each cell contains a numerical representation of the words frequency of use or some other metric.
 Summary of text cleaning steps.
Summary of text cleaning steps.
The final data format is “fit” on the initial dataset, and then applied to any incoming data (as is the case with the search engine feature described later in this post.)
To elaborate a bit on vectorization: I focused on trying out two types/implementations of vectorization in scikit-learn:
- Count Vectorizer, which simply counts the frequency of each word in each document/transcript.
- TF-IDF Vectorizer, which calculates the product of term frequency with its inverse-document frequency (a scale of 0 to 1 where values closer to zero are common in the entire dataset of transcripts). This is a valuable metric because it weights words that are common in a document more heavily if they aren’t common in general, which is a useful tool for ultimately extracting distinct topics.
In general, creating this pipeline was an iterative process. I tried out different transformations and did topic modeling (explained in the next section) to evaluate the effectiveness of different components in the pipeline. This helped inform my decision to vectorize the text with TF-IDF, as it yielded topics that were much more discernible and easy to label by looking at each topic’s top words.
One other note important note is that using pre-built lists of common English stop words to remove from the dataset isn’t a complete solution. I had to do quite a bit of combing through the transcripts to identify insignificant, yet common words and manually add them to the stop words list. It may come as no surprise that curse words are extremely prevalent in comedy, and don’t usually add much meaning, so I had to include some pretty aggressive words in my code (several of which are fairly offensive and I wouldn’t use in conversation).
Aside from also removing names/other irrelevant proper nouns, I also had to carefully decide what to do about racial slurs. Like it or not, racial slurs are common in stand-up comedy and can sometimes carry important meaning with regards to a comedian’s jokes. As a result, I left many of them in the dataset, but was also tasked with the uncomfortable task of hard-coding some extremely antiquated language in the NLP pipeline class for removal.
Modeling & Flask App Features
My main objective for this project was to develop a Flask application that provided more nuanced recommendations of comedy specials than what’s currently available on mainstream streaming platforms. I scoped out two features:
- A dropdown genre filter using genres that were created by machine learning algorithms (as opposed to human labeling.)
- A search bar that allows a user to describe the comedy they want to see, and get content-based recommendations.
You can play around with the app here.
Automatic Genre Filters with Topic Modeling
Creating machine-learned genres involves first applying the unsupervised learning technique of topic modeling, transforming the resulting data to extract which words are most closely related with each topic, and then performing the manual task of giving each topic a reasonable label.
In relatively simple terms, topic modeling involves reducing the dimensions of the document-term matrix (words) to a specified number of columns (representing the topics, and a weighting for each topic to each document). I tried a few different dimensionality reduction techniques including Latent Semantic Analysis (LSA), Latent Dirichlet Allocation (LDA), and Non-Negative Matrix Factorization (NMF). Ultimately, the scikit-learn implementation of NMF yielded the most discernible topics.
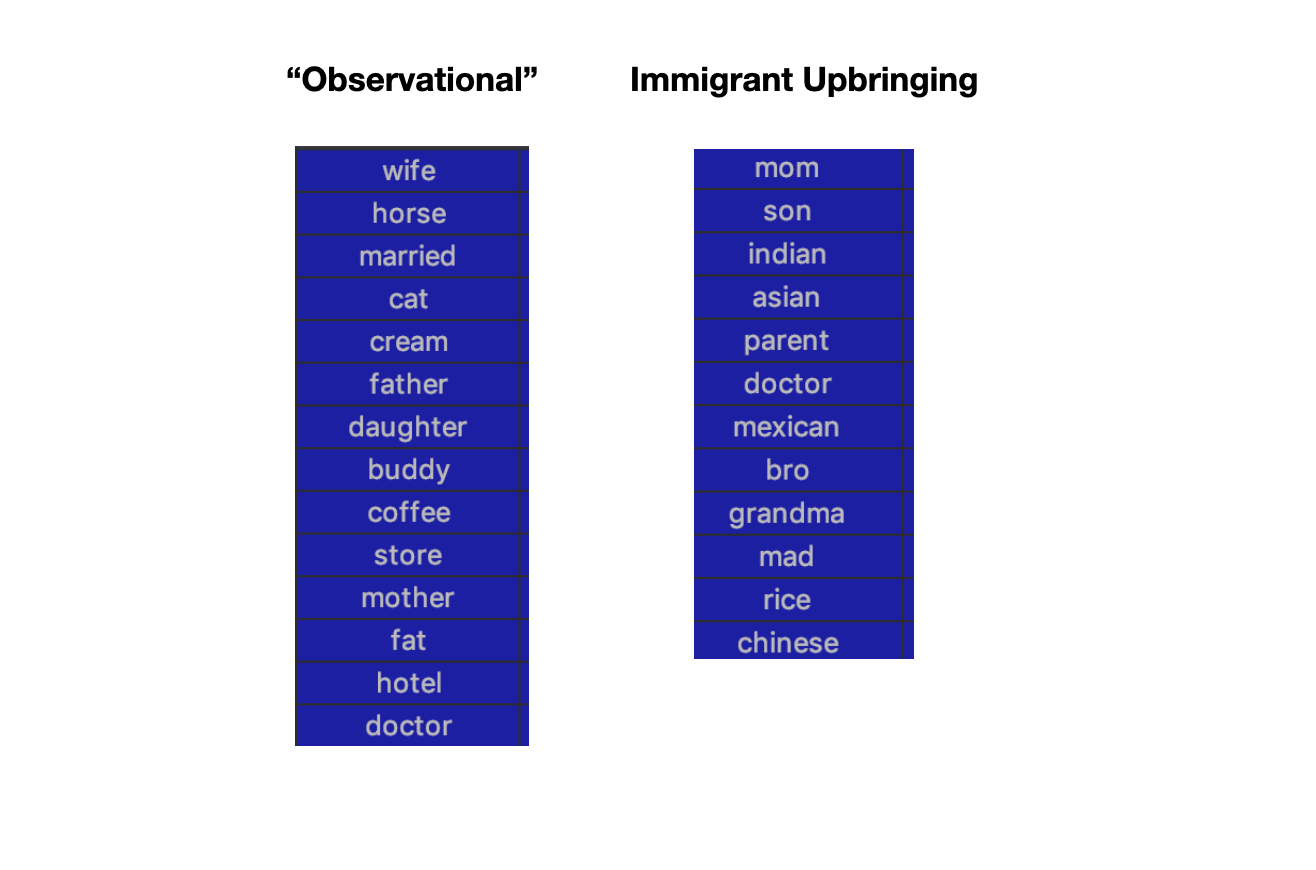 Examples of top words associated with modeled topics.
Examples of top words associated with modeled topics.
Based on the top words generated from each topic, I used my knowledge of comedy to select the following genres:
- Observational: This is sort of a catch-all for “average”, “every day” topics such as family, chores, marriage, pets, etc. This type of comedy is quite common.
- Immigrant Upbringing: Many comedians are 1st generation Americans with parents that immigrated to the US and brought their culture with them. Comedians with recently immigrated families often talk about the humorous struggles of assimilation, the quirks of their various cultures, the pressures of their parents, and hardworking nature of their families.
- Relationships & Sex: This is another very common topic in comedy, particularly for “dirty” comedians. The sub-topics range from dating, to LGBTQ humor, and heavily sexual jokes.
- British/Australian: This topic was selected almost entirely based on colloquialisms of the comedian. While the United Kingdom and Australia have different cultures, they share some slang in common. If I were to continue to spend time on this project, I would probably try and separate these two topics, as British comedy historically is associate with a specific type of “dry” humor. That being said, many non-American english-speaking comedians share a common tendency to have more solid “themes” in their comedy specials as opposed to a random assortment of jokes.
- The Black Experience: I put a decent amount of effort into being sensitive around this topic. (Coincidentally, I was working on this project during the height of the protests in the wake of the murder of George Floyd by police in Minneapolis). Traditionally, Black comedians have been lumped into the genre of “Urban” comedy. While the “Urban” comedy scene is extremely rich in culture, that word seems to exist as an unnecessary euphemism. It is important to consider how a machine learning algorithm might be biased in a way that might marginalize groups of people. Additionally, I recognize that there is no such thing as a “monolithic black experience” - every individual has their own experience. All that being said, I still felt that this was a valid genre since Black Americans have collectively experienced many things throughout history from slavery, to segregation, to police brutality (and everything in between). And most impressively Black comedians have turned these issues and events on their head through humor and comedy to create dialogue (while entertaining people).
An important technical note here is that these genres are not exclusive to each comedy special in the data set - a comedy transcript can belong to multiple genres. Each comedy special is assigned a weight for each topic/genre, and considered “belonging” to that genre if the weight is above some threshold.
I put the genres in a dropdown menu in the Flask application. When a user selects a genre, Javascript code runs to filter out any comedy specials that are below a topic weight threshold of 0.2 for that genre.
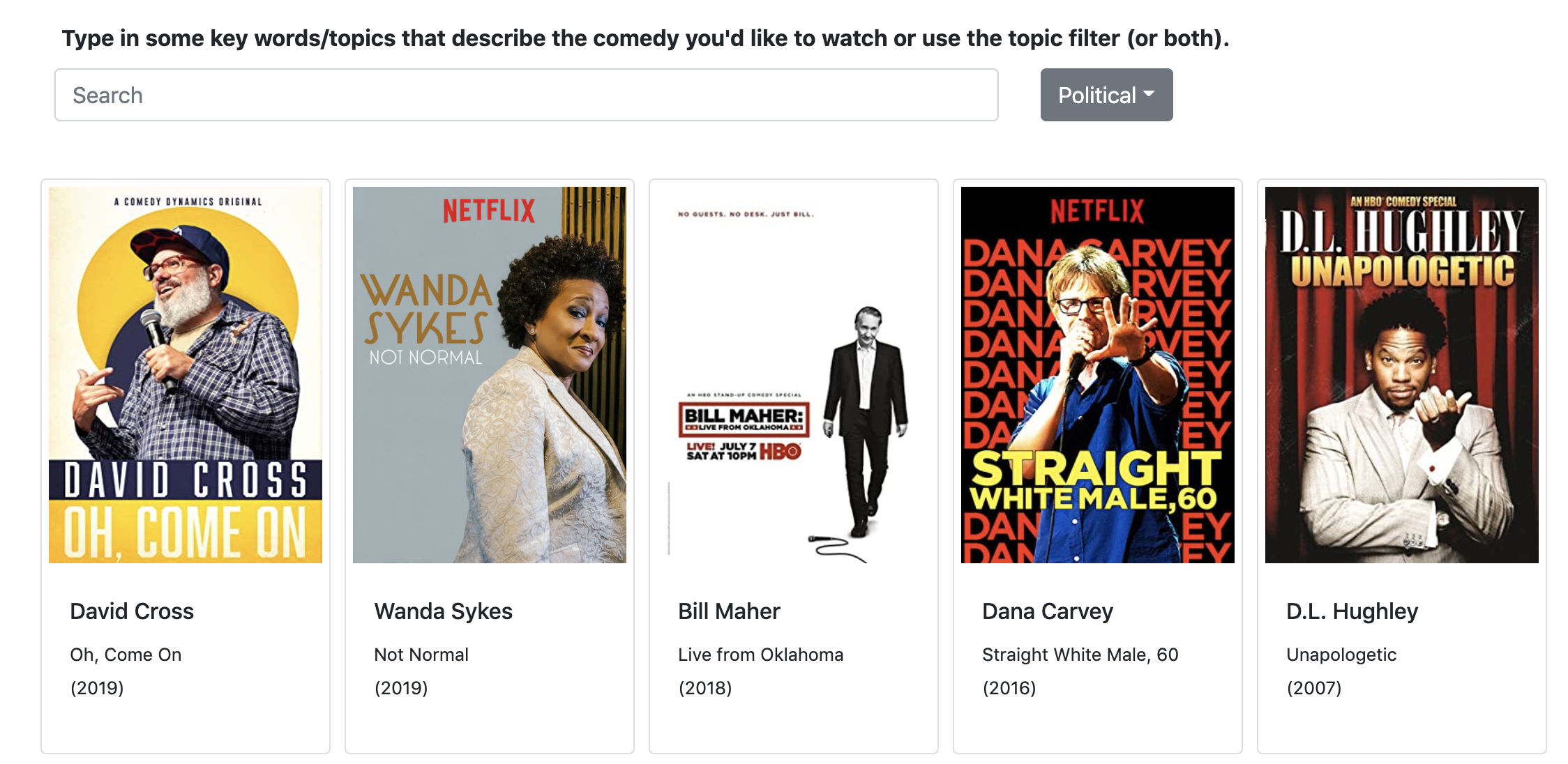 Filtering comedy by genres generated through topic modeling.
Filtering comedy by genres generated through topic modeling.
Search Engine Recommender with Content-Based Filtering
The second feature was an opportunity for me to build my first recommender system with content-based filtering. My Flask app doesn’t have a large user base or any sort of “rating” functionality, so obviously collaborative filtering was not an option.
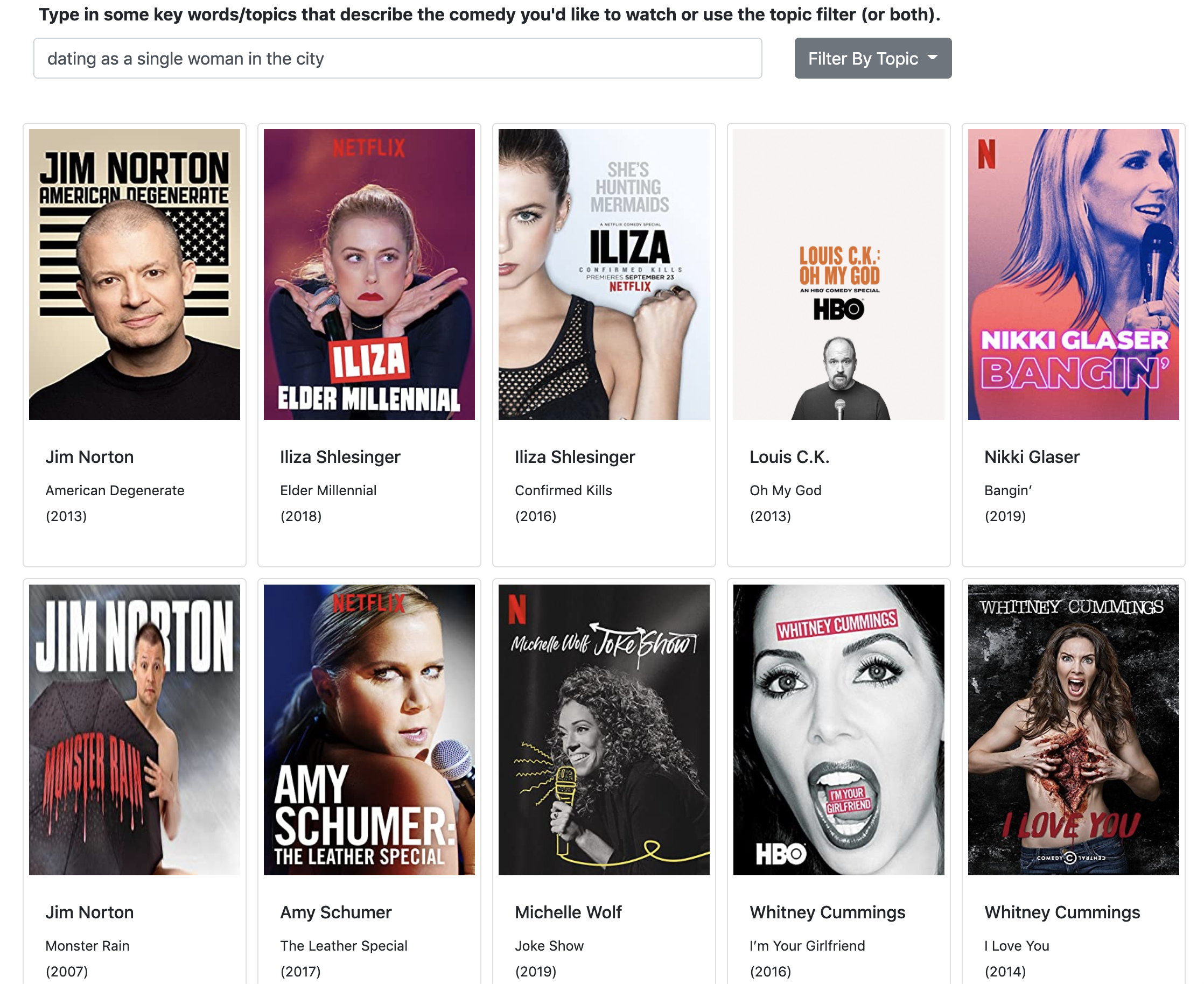 Search term recommender with content-based filtering
Search term recommender with content-based filtering
The main input to the recommender is a text field for which the user is asked to describe the type of comedy they want to see. When the user submits the text, it is treated similarly to a document from the main corpus: cleaned, transformed, and vectorized to the same format. It is then transformed using the NMF pre-fit on the comedy transcript corpus and assigned weights for each of the five topics.
Finally, the cosine similarity is calculated between the search term topic weights and each document (comedy special) in the transcript’s topic weights. The top 10 comedy specials with the largest cosine similarity with respect to the search term are recommended to the user.
Final Thoughts
Before learning about NLP or working on this project, I never thought of language as something that can be broken down, quantified, and processed by linear algebra. However, by using mathematical techniques and allowing a computer to determine patterns in human speech, we can learn a lot about how language works and what makes us laugh or identify with a particular set of thoughts.
This project also presented me with an ethical challenge when an unsupervised learning algorithm outputted comedy genres that fell within cultural and ethnic bounds. I got a lot out of learning to carefully navigate sensitive words, topics, and potential algorithmic bias.